朴素RAG简明回顾
背景:回顾一下RAG.
RAG
检索增强生成(Retrieval-Augmented Generation,RAG)是一种模型架构。它结合了检索和生成的思想,核心思路是通过检索召回相关内容(检索),结合用户相关信息输入大模型(增强),最终生成答案(生成)。
本质是通过对外部知识来源的集成在大模型交互过程中的prompt增加相关性信息,使得大模型生成更精确和上下文感知的响应,同时也有效抑制幻觉。
Naive RAG(朴素RAG)
检索外部知识,添加相关上下文。
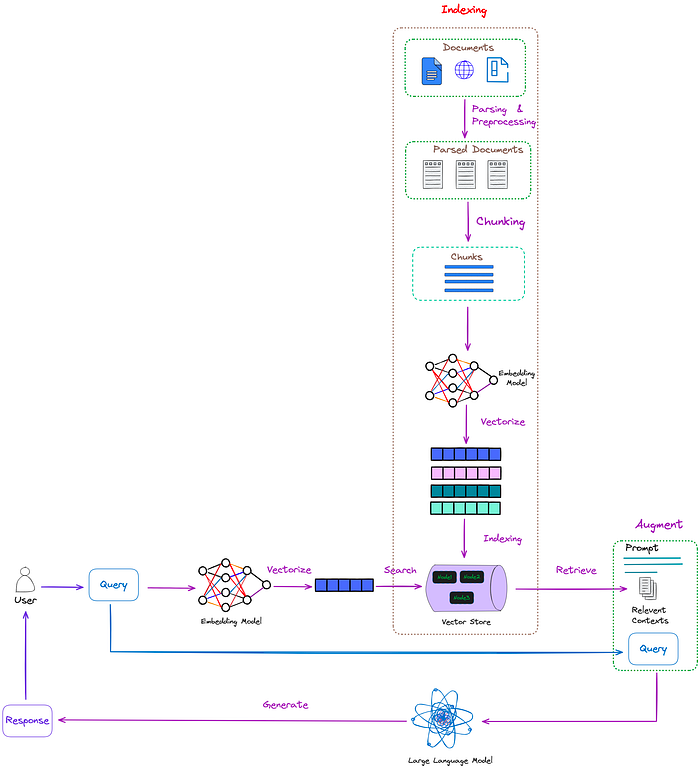
流程
朴素RAG的三个步骤:
-
索引(indexing):索引过程是离线执行的关键初始步骤。
-
输入标准化,清理和提取原始数据,将各种文件格式(如PDF、HTML和Word)转换为标准化的纯文本;
-
文本切块(chunk),以适应语言模型的上下文约束;
-
Embedding,使用Embedding模型将这些块转换为向量表示;
-
索引构建,将这些文本块及其向量Embeddings存储为键值对,从而实现高效和可扩展的搜索功能。
-
-
检索(Retrieval):用户查询用于从外部知识来源检索相关上下文。
- 用户查询由编码模型处理,该模型生成语义相关的Embeddings;
- 在向量数据库上进行相似性搜索,检索最接近的k个数据对象(top k)。
-
生成(Generation):将用户查询和检索到的附加上下文填充到prompt模板中。最后,将检索步骤得到的增强prompt输入到LLM中。
示例Prompt
请回答后面用三个反引号 ```{query}``` 包围的问题,
回答时参考用三个反引号 ```{context}``` 包围的参考信息。
如果提供的上下文中没有相关信息,尝试自己回答,但要告诉用户你没有相关的上下文作为回答的依据。
回答要简洁,输出的答案少于80个token。
问题
朴素RAG在上面提到的所有三个步骤中都存在一定问题。
Indexing(索引)
-
信息提取不完整,不能有效处理非结构化文件(如PDF)中的图像和表格中的有用信息;
-
文本切块,“一刀切”策略,定长切块,而不是根据不同文件类型/业务场景选择最优策略;
语义割裂,每个块包含不完整的语义信息;
-
文本切块,没有考虑结构化信息,例如文档文本中存在的标题、目录、序、附录等;
这部分信息没利用起来
-
索引结构没有充分优化,导致检索效率低下;
-
Embedding模型的语义表示能力较弱;
Retrieval(检索)
-
回忆上下文的相关性不足,准确性低;
低精度,即检索集中的文档块并不都与查询内容相关,这可能导致信息错误或不连贯。
-
低召回率阻碍了所有相关段落的检索,从而阻碍了大语言模型生成全面答案的能力;
低召回率,即未能检索到所有相关的文档块,使得大语言模型无法获取足够的背景信息来合成答案
-
查询可能不准确或Embedding模型的语义表示能力较弱,导致无法检索到有价值的信息;
-
检索算法的局限性在于没有结合不同类型的检索方法或算法,如组合关键字检索、语义检索、向量检索等;
-
当多个检索上下文包含相似的信息时,会出现信息冗余,导致生成的答案中的内容重复;
数据冗余或过时可能导致检索结果不准确
Generation(生成)
增强式生成过程所面临的主要挑战是:如何将检索到的文段的上下文有效融入当前的生成任务。
如果处理不得当,生成的内容可能显得杂乱无章。当多个检索到的文段包含相似信息时,冗余和重复成为问题,这可能导致生成内容的重复。
- 可能无法有效地将检索到的上下文与当前生成任务集成,从而导致输出不一致;
- 在生成过程中过度依赖增强信息存在较高风险。这可能导致输出只是简单地重复检索的内容,而不提供有价值的信息;
- LLM可能会产生不正确、不相关、有害或有偏见的反应;
最后,三个步骤的问题会统一在响应上爆发,因此 工程环节上的链路Trace是必要的。
如果LLM响应了一个不相关回答,可能是LLM本身提取能力问题,也可能是数据源文本提取、Embedding模型无法准确捕获语义、索引检索、索引召回等。
