高级RAG简明回顾
背景:续接前文,朴素RAG的基本思想在工程上没问题,但值得优化的点还是较多。
前几天,首届OpenAI开发者大会,发布GPT-4 Turbo 128k、GPT-4 Turbo with Vision、GPT-3.5-turbo-16k、DALL·E 3等多个模型的开发API,更新的语料库,更低的价格。多模态大模型趋势明显。
Advanced RAG(高级RAG)
相较于 Naive RAG,增加了下面优化:
- “Pre-Retrieval”(检索前)优化,例如:细粒度数据清洗、添加文件结构以及查询重写/澄清等。
- “Post-Retrieval”(检索后)优化,从向量数据库检索后的优化,例如:重排序、过滤和提示压缩等。
Pre-Retrieval
Parser Router
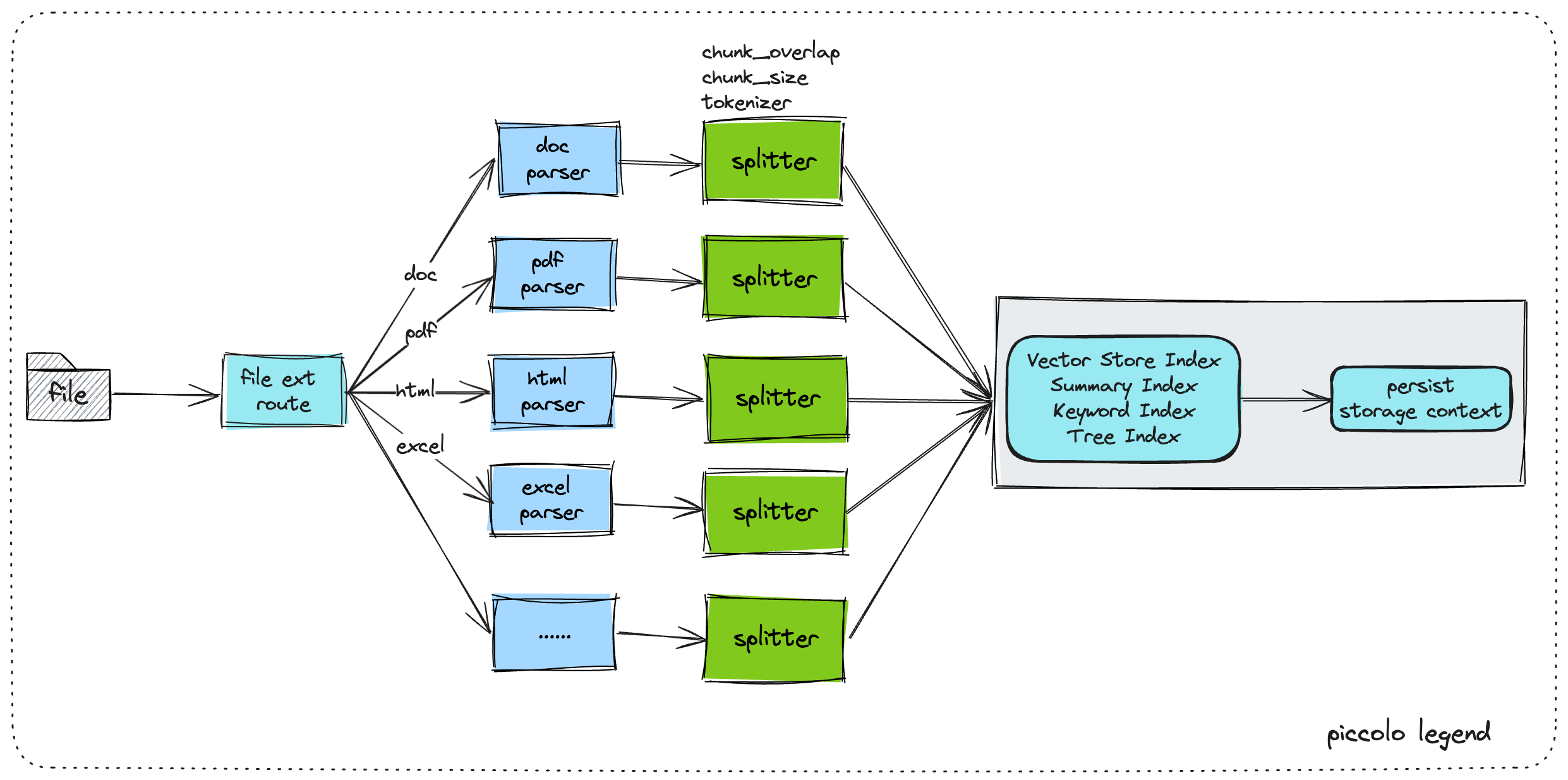
1.Rule-based Parser Router
典型的一种就是,洗数据阶段基于文件类型制定不同的parser及splitter去切chunk,以更好地保证提取文本的有效性。
典型的索引构建过程:
设置文件类型的parser路由及splitter切分策略,如下图。
2.Model-based Parser
特别地,部分业务场景中的存在复杂文件,以pdf为例,往往真实业务场景中存在pdf扫描件,难以直接解析获取比较好的效果,此时可增加业务判断链路去基于模型做pdf解析。
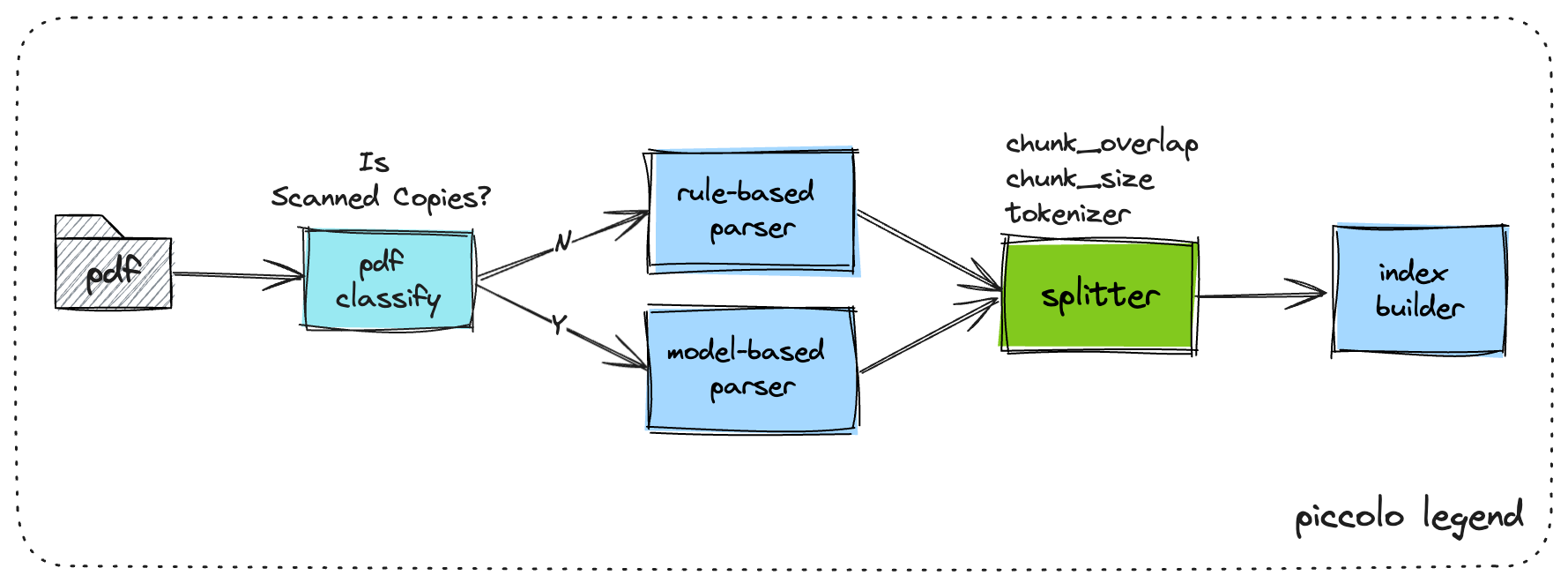
其parser具体实现可以通过以下案例尝试。
- pdf按页转png;
- bounding box之类的目标检测;
- OCR;
- Table scan;
基于模型的parser需要针对一些双栏的pdf的样本做训练,以保证pdf的数据块文本顺序。
3.LLM Parser
多模态大模型,可以支持文件形式解析并给出结构化数据返回;也可以对文档进行按页切分后进行OCR识别后,文本丢给大模型进行问答查询。
LLM parser效果在多模态文档上,确实表现比前两者好些,但是贵且慢。
当多模态大模型能力愈来愈强,API价格更合适时,LLM parser的性价比才会更好。
文档结构信息增强
典型的结构信息有:
-
文档本身的目录、序、附录等文档内结构;
parser中增加对文档的结构化解析
-
文档父路径及同路径同层级都有哪些文档;
同一folder内文档 往往具备一定联系
查询改写
查询改写工程上使用的有以下几个方面
- [转换]将连续多轮、口语化的用户查询转换为搜索引擎更容易理解的关键词或语义结构;
- [推断]推断用户问题背后的更深的问题进行内容拓展,更好地理解用户意图;
- [过滤]规则化针对业务制定敏感词过滤及业务红线词等;
Post-Retrieva
Rerank
重排的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确和相关答案的上下文。
工程中会发现,特别是对于文档切分后的召回,直接召回的质量并不会很高。特别地,对于实际中某些index,构建时将一句QA对切割为Q和A,召回却只召回了Q而没有A,而且召回后的top N排序还比较靠前。对这种切chunk出现的语义丢失,是常有的事。
-
小模型Rerank
小模型对排序任务的训练
-
LLM Rerank
-
一种简单LLM Rerank实现,prompt中输入可选集和问题 直接与LLM交互 实现ReRank。
-
对一个LLM做重排任务的微调
-
Prompt Reduce
prompt一般会包含问题和背景,而背景中往往存在不少LLM已经学习过的内容或冗余描述。由于LLMs在训练的过程中很大概率已经见到过类似内容的文本,所以这些内容并没有带来新的信息。因此,适当合理的prompt 压缩可以塞下更多有效context。
summary & merge
多路索引召回后的结果,再进行总结与融合。可以直接请求LLM完成此任务。
后记
最近在拉通某个项目的工程链路,有时候陷入的思考。对整个RAG范畴来讲,优化的本质始终落在:
-
数据源出发 更有效高效的提取信息(包括 图、表等) 做到 少遗漏;
这部分很重,针对表格信息,除了识别外 还涉及一定计算量;
-
更智能的chunking策略 比如能智能判断文件的内容稀疏与稠密进行范围内的优化切分;
除了内容稀疏程度外,也许chunking策略可以一定程度让用户使用时传入。
-
更优质的召回质量与Rerank;
召回时的窗口大了又容易重叠且召回过多,小了又可能遗漏;
-
多轮会话处理上 更稳定可靠的总结提取;
