Prompt简明回顾
背景:搞了一段时间相关的LLM应用,简单回顾一下LLM Prompt.
LLM & Prompt
LLM
截止2023/07/19,已经有15821个LLM发布至Hugging Face
https://arxiv.org/abs/2307.09793
通常认为参数量超过10B的语言模型为大语言模型。由于参数量巨大,需要的训练数据量也极多,因此目前大部分的应用方式为:大公司整理大量常用数据集,训练一个各方面性能还不错的通用大模型,比如: ChatGLM,应用方直接调用通用大模型或在此通用模型上搜集小规模行业数据进行微调,最终得到行业专有模型/领域模型。
当然,如果通用模型能直接拥有各行业知识是最好的,但以目前的数据量和算力等还未达到效果。
LM 分类

Transformer语言模型的分类,一般分为三种:自回归模型、自编码模型和序列到序列模型。
自回归(Autoregressive model)模型采用经典的语言模型任务进行预训练,即给出上文,预测下文,对应原始Transformer模型的解码器部分,其中最经典的模型是GPT。由于自编码器只能看到上文而无法看到下文的特点,模型一般会用于文本生成的任务。
自编码(AutoEncoder model)模型则采用句子重建的任务进行预训练,即预先通过某种方式破坏句子,可能是掩码,可能是打乱顺序,希望模型将被破坏的部分还原,对应原始Transformer模型的编码器部分,其中最经典的模型是BERT。与自回归模型不同,模型既可以看到上文信息,也可以看到下文信息,由于这样的特点,自编码模型往往用于自然语言理解的任务,如文本分类、阅读理解等。(此外,这里需要注意,自编码模型和自回归模型的唯一区分其实是在于预训练时的任务,而不是模型结构。)
序列到序列(Sequence to Sequence Model)模型则是同时使用了原始的编码器与解码器,最经典的模型便是T5。与经典的序列到序列模型类似,这种模型最自然的应用便是文本摘要、机器翻译等任务,事实上基本所有的NLP任务都可以通过序列到序列解决。
目前现有的LLM基本上全是自回归(Autoregressive model)
![]()
LLM 分类
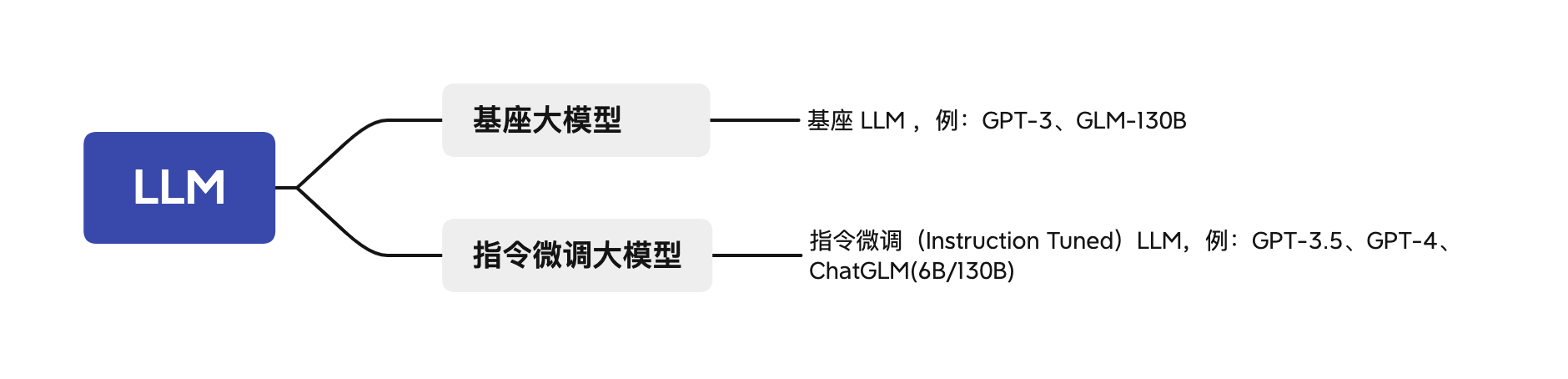
LLM大致可以分为两类,基座大模型和指令微调大模型(Instruction Tuned LLM)。
基座大模型,也可称为预训练语言模型,是基于文本训练数据,训练出预测下一个单词能力的模型。其通常通过在互联网和其他来源的大量数据上训练,来确定紧接着出现的最可能的词。例如,如果你以“从前,有一只独角兽”作为 Prompt ,基础 LLM 可能会继续预测“她与独角兽朋友共同生活在一片神奇森林中”。但是,如果你以“法国的首都是什么”为 Prompt ,则基础 LLM 可能会根据互联网上的文章,将回答预测为“法国最大的城市是什么?法国的人口是多少?”,因为互联网上的文章很可能是有关法国国家的问答题目列表。
| 模型名称 | 发布时间 | 发布机构 | 语言 | 参数规模 | Tokens规模 | 模型结构 | 是否开源 |
|---|---|---|---|---|---|---|---|
| GPT-3 | 2020-05 | OpenAI | 英 | 175B | 300B | GPT-style | 否 |
| GLM-130B | 2022-08 | Tsinghua | 中、英 | 130B | 400B | GLM-style | 是 |
| OPT | 2022-05 | Meta | 英 | 125M-175B | 180B | GPT-style | 是 |
指令微调大模型,相关研究和实践正甚嚣尘上,训练它们来遵循指示。因此,如果你问它,“法国的首都是什么?”,它有极大可能输出“法国的首都是巴黎”。指令微调的LLM的训练通常是基于预训练好的LLM的,即模型已经在大量文本数据上进行了训练。然后对其进行进一步训练与微调(finetune),使用的数据包括输入和理想输出(输入是指令、输出是遵循这些指令的良好回答)。然后通常使用一种称为 RLHF(reinforcement learning from human feedback,人类反馈强化学习)的技术进行进一步改进,使系统更能够有帮助地遵循指令。
| 模型名称 | 发布时间 | 发布机构 | 语言 | 模态 | 参数规模 | Tokens规模 | 模型结构 | 是否开源 |
|---|---|---|---|---|---|---|---|---|
| GPT-3.5 | 2021-06 | OpenAI | 多语言 | 文本 | 175B | 4K | GPT-3 | 否 |
| ChatGPT | 2022-11 | OpenAI | 多语言 | 文本 | 173B | GPT3.5 | 否 | |
| GPT-4 | 2023-3-14 | OpenAI | 多语言 | 文本、图像 | 1800B(网络猜的) | 8K | GPT-4 | 否 |
| ChatGLM | 2023-3-14 | Tsinghua | 中、英 | 文本 | 6B/130B | GLM | 6B版本开源 |
因为指令微调的 LLM 已经被训练成有益、诚实、无害的,所以与基座大模型相比,它们更不可能输出有问题的文本,如有害输出。许多实际使用场景已经转向指令微调的大模型 。
您在互联网上找到的一些最佳实践可能更适用于基础 LLM ,但对于今天的大多数实际应用,我们建议将注意力集中在指令微调的 LLM 上,这些 LLM 更容易使用,而且由于 OpenAI 和其他 LLM 公司的工作,它们变得更加安全,也更加协调。
当您使用指令微调 LLM 时,您可以类比为向另一个人提供指令(假设他很聪明但不知道您任务的具体细节)。因此,当 LLM 无法正常工作时,有时是因为指令不够清晰。例如,如果您想问“请为我写一些关于阿兰·图灵( Alan Turing )的东西”,在此基础上清楚表明您希望文本专注于他的科学工作、个人生活、历史角色或其他方面可能会更有帮助。
LLM 绕不开的一张发展图

LLM工程应用
实际项目落地过程中,往往存在大模型没有最新数据或没有学习过业务场景中的知识,而对业务场景不可直接使用。LLM获取知识的方式有两种,一种是模型内置的知识,一种则是外部知识。因此,模型在业务中的落地也出现了两种优化手段。
-
微调(Finetune) 微调通过对特定领域数据集进行广泛的训练来调整整个模型,用以内化细分领域知识。
-
检索增强生成(RAG) RAG 检索外部知识来提取上下文并经过排序給模型响应,使训练轻量化。
二者对比如下,简明地说明,RAG在场景下的幻觉抑制与可解释性都优于Finetune,且可快速迭代新的业务知识,类似于外挂知识库;Finetune则更适用于一些特定的知识相对固化领域,训练阶段需要一个大型且高质量的标记数据集,训练后场景下的幻觉并不能保证得到很好的抑制。
| Finetune | RAG | |
|---|---|---|
| 是否需要GPU资源 | 是 | 否 |
| 是否需要外部知识 | 否 | 是 |
| 更新知识方式 | 重新训练 | 更新embedding |
| 开发周期 | 长 | 短 |
| 适合场景 | 赋予大模型某种能力, 业务知识相对固定的场景 |
直接赋予大模型某种知识,可快速更新, 业务知识不断变化的开放场景 |
| 推理速度 | 高于RAG | 慢于Finetune |
| 结果准确度 | 高于RAG | 低于Finetune |
| 透明度和可解释性 | 低于RAG | 高于Finetune |
| 业务内 幻觉抑制 | 低于RAG | 高于Finetune |
LLM如何交互
主要思考两个问题
Q1:如何与计算机交互?
A:CLI -> GUI的转变
Q2:如何与大模型进行交互?
A:
大模型的WEB界面 键入问题文本;
开发人员还可API调用;

通俗地讲,将大模型比做一个强大的搜索引擎+特殊的计算设备组合,那么,对于大多数使用者而言,Prompt就是就是问题指令交互界面。
CLI(Command Line Interface):命令行界面。CLI是在图形用户界面得到普及之前使用最为广泛的用户界面,以键盘为输入源(不支持鼠标),用户通过键盘输入指令,计算机接收到指令后,予以执行。也有人称之为字符用户界面。CLI在工程师群体中,目前仍然使用非常广泛。
GUI(Graphical User Interface):图形用户界面。GUI是指采用图形方式显示的计算机操作用户接口。与早期计算机使用的命令行界面相比,图形界面对于用户来说在视觉上更易于接受。GUI和CLI最大的不同是,GUI引入鼠标为输入源(后期又以触屏为输入)。
NUI(Natural user interface):自然用户界面。NUI主要指在GUI的基础之上,输入源开始脱离鼠标、键盘等传统图形界面输入设备的全新交互方式。
狭义NUI:是指以苹果为代表的厂商掀起的一股对GUI的升级改造活动,狭义的NUI依然以图形界面为基础,但通过改进输入方式(电容屏、多点触控、滑动)等更为自然的方式交互,使的用户操作更为自然,往往2、3岁的儿童就能掌握操作的要点。
广义NUI:是指利用“手势”“语音”“视觉”“姿势”“感知”等一系列更自然的方式,同计算机(机器人)进行交互。其特点是借助于多维度的“自然”输入,和人工智能的技术,实现人与机器人的双向交互。目前,新能源领域的车机交互则大量使用语音、手势、人体姿态等进行NUI交互。
Prompt
在语言模型(例如 GPT-3)中,“prompt” 指的是用户向模型提供的输入文本或提示。在进行与模型的交互时,用户可以通过编写一个包含问题、指令或上下文信息的提示来引导模型生成所需的回应。在 GPT-3 中,用户通常通过 prompt 与模型进行对话或提出问题,以获得相应的输出。prompt 的设计和表达方式对于引导模型生成合适的响应至关重要。
当然,这里也可以将问题抛给大模型,问大模型自己:Prompt是什么。
使用bito插件,发起提问。

案例
https://github.com/openai/openai-python/tree/v1.9.0
from openai import OpenAI
GPT3_API_KEY = "sk-joiuxxxxxxx"
def ask_llm(prompt, model="gpt-3.5-turbo"):
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=GPT3_API_KEY,
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": prompt,
}
],
model=model,
)
# print(chat_completion)
return chat_completion.choices[0].message.content
question = "讲一个中文成语典故吧?"
resp = ask_llm(question)
print(resp)
成语“柳暗花明”源自《红楼梦》,原文是“我以后必有柳暗花明之日”。这句话出自曹雪芹笔下贾宝玉对林黛玉说的话,意思是虽然眼前看到的是痛苦与阴暗,但是将来一定会有转机和希望。这成语后来被用来形容出现不顺利之际,随后就会有好转的局面,给人以希望和坚定。
Prompt 的基本位面: 提示词
其实个人觉得提示词这个翻译不是很准确。
典型机器学习开发的流程,通常是先有一个想法,然后再用以下流程实现:
编写代码->获取数据->训练模型->获得实验结果
然后您可以查看结果,分析误差与错误,找出适用领域,甚至可以更改您对具体问题的具体思路或解决方法。
此后再次更改实现,并运行另一个实验等,反复迭代,最终获得有效的机器学习模型。
基于大模型的应用开发流程
编写Prompt->请求LLM->得到结果
围绕Prompt不断尝试,迭代,得到一个比较有效的Prompt。特别地,会有预训练,让通用的大模型在指定领域内补充相关知识。
大模型应用研发中,比较影响模型效果的往往就是: Prompt Engine 与 模型预训练/微调。因此,了解Prompt的基本位面特点是非常有必要的。
Prompt 标准式
Prompt example网站:
首先,大多数的提示词(prompt)通常包含两个部分:指令(instruction)和内容(content),下文记作标准式。

在这种结构中,指令部分指明用户希望大模型执行的任务,比如“请判断下列句子中的情感倾向”;而内容部分则包含实际的上下文,比如“午饭不错,我挺高兴”。但需注意的是,并非所有的Prompt都符合标准式,有些简短的Prompt只包含向LLM下达的指令而无内容,视作内容为空即可。

Prompt 分类
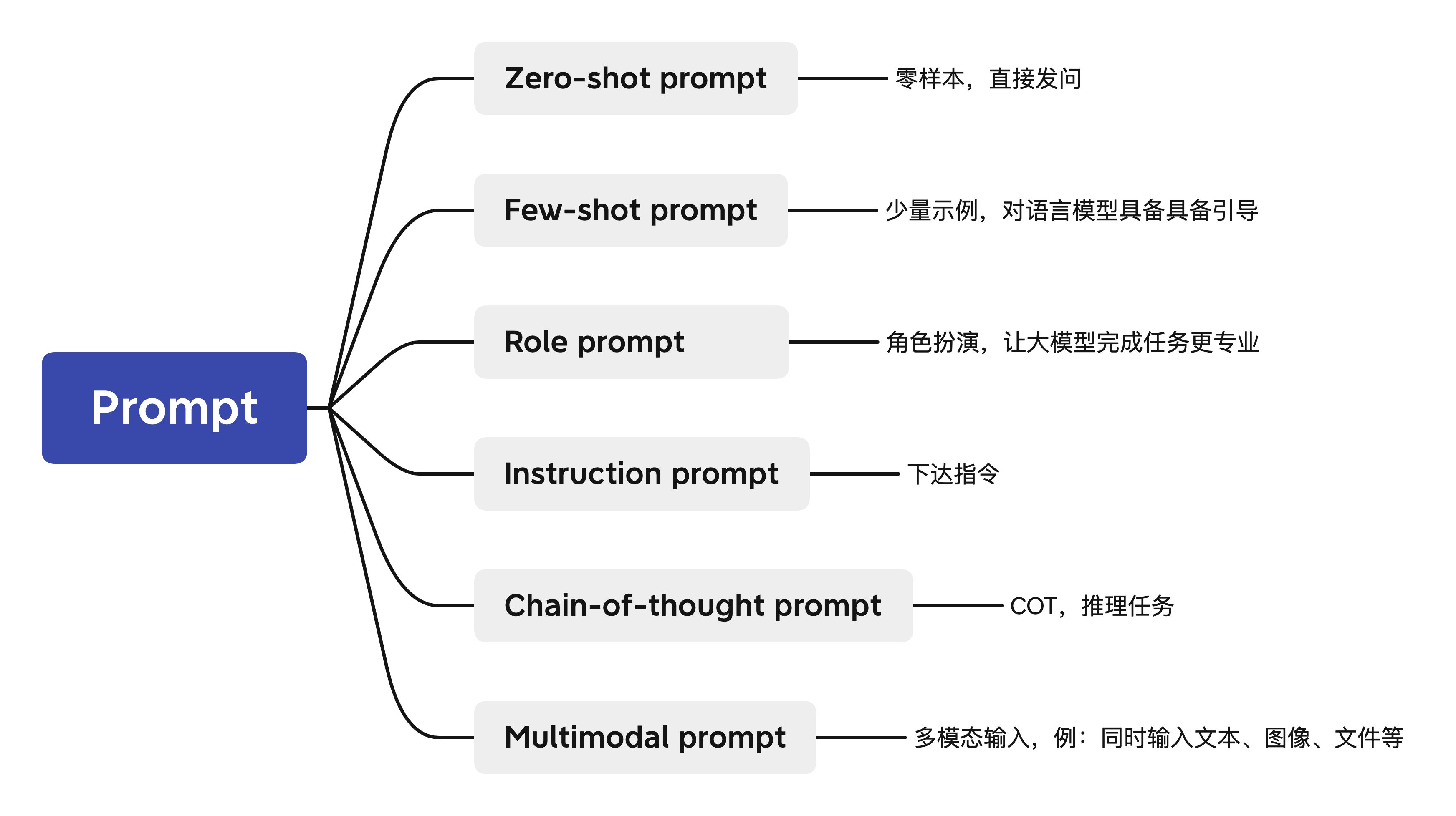
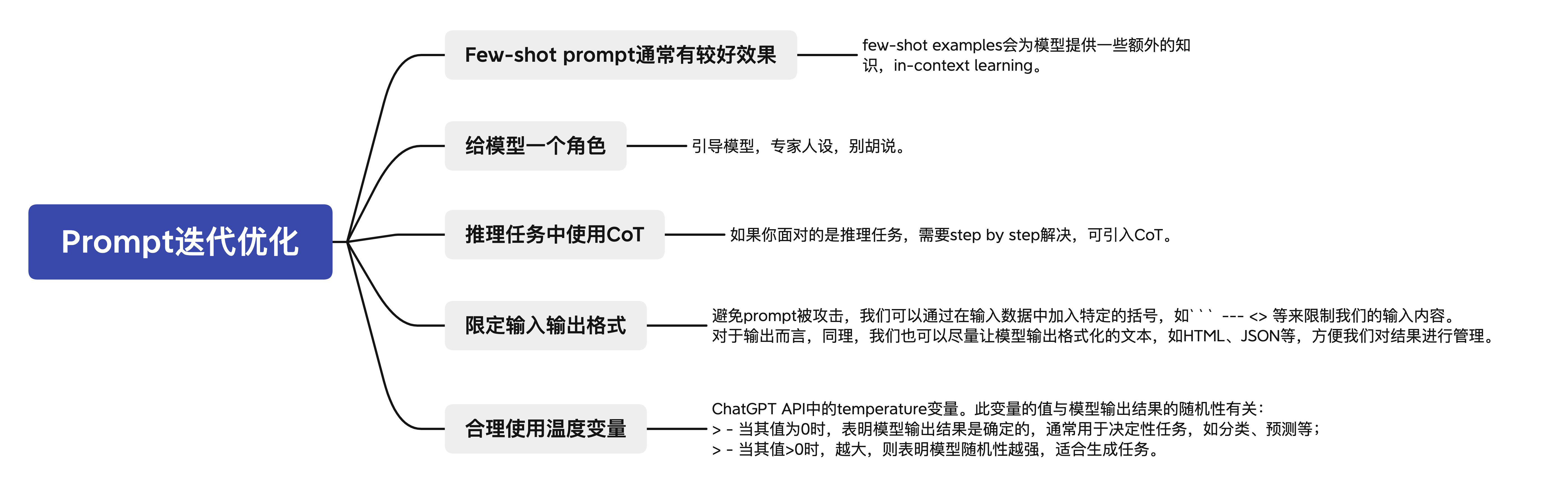
- Zero-shot prompt: 零样本的prompt。
此为最常见的使用形式。之所以叫zero-shot,是因为我们直接用大模型做任务而不给其参考示例。
这也被视为评测大模型能力的重要场景之一。
- Few-shot prompt: 与zero-shot相对,在与大模型交互时,在prompt中给出少量示例。
此场景目前应用广泛,典型的有RAG。
- Role prompt: 与大模型玩“角色扮演”游戏。可以让給大模型预设为某方面专家,让其代入,因而获得更好的任务效果。
prompt示例
扮演Microsoft SQL Server 要求: - 创建一个名为“politics”的数据库,并在其中创建一个名为“politicians”的表。从不同时代的世界各地的著名政治家中填充50行,时间范围为1900年至2000年。 - 添加他们的全名、国家、出生日期和适用的死亡日期的列。-为活得最久的前3位政治家创建一个视图。 - 创建并执行一个Transact-SQL命令,输出该视图的内容。
- Instruction prompt: 指令形式的prompt。
无上下文式直接发问
- Chain-of-thought prompt: 常见于推理任务中,通过让大模型
Let's think step by step来逐步解决较难的推理问题。
CoT是目前工程上解决复杂问题比较标准的解决范式,但泛化性效果可能并不是那么地好(这里非常依赖基座大模型的能力)。这里最近在工作中具体的项目落地中也可以观察到,链式分解后,链路前端某一个环节的Prompt微小改动对整个链路的准确率影响可能会是毁灭性的。
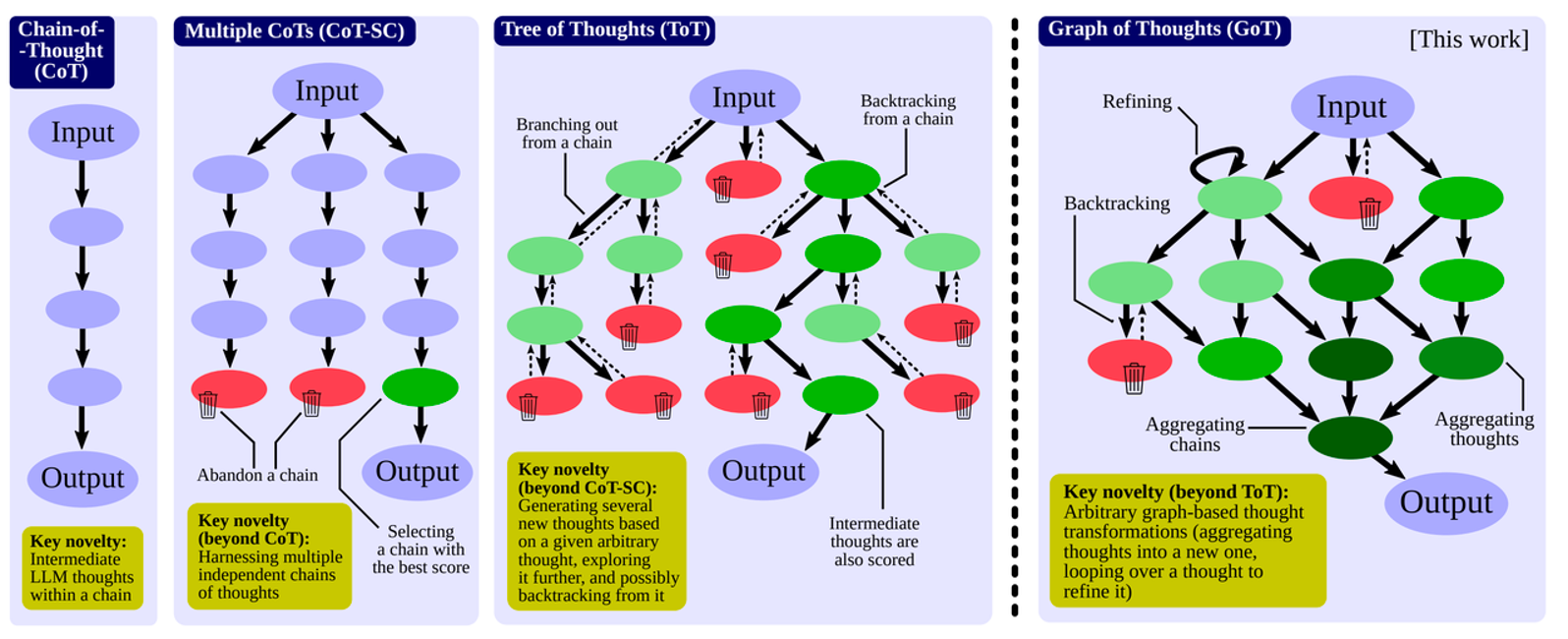
拓展:Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Desc Cot 推理任务的链式拆解 Cot-SC 多链,横向扩展; ToT 树化推理 GoT DAG 图化推理
- Multimodal prompt: 多模态prompt。顾名思义,输入不再是单一模态的prompt,而是包含了众多模态的信息。如同时输入文本和图像与多模态大模型进行交互。
Prompt 迭代优化
主要围绕Prompt特点来的。
LLM 应用范式
文本概括
LLM在文本概括任务上表现出强大能力。 此处,用作工程上可用作:
- 参数提取
- 意图识别
情感分析
- 任务分类
content="这个产品质量很好,快递也快,价格合理,最主要是客服全程态度很棒。"
prompt = f"""
您的任务是从电子商务网站上生成一个产品评论的简短摘要。
请对三个反引号之间的评论文本进行概括,最多30个词汇。
评论: ```{content}```
"""
ask_llm(prompt)
摘要:产品质量好,快递快,价格合理,客服态度棒。
content="这个产品质量很好,快递也快,价格合理,最主要是客服全程态度很棒。"
prompt = f"""
您的任务是从电子商务网站上生成一个产品评论的简短摘要。
请对三个反引号之间的评论文本进行概括,最多30个词汇。
侧重点:快递时效性
评论: ```{content}```
"""
ask_llm(prompt)
快递快,产品质量好,价格合理,客服态度棒。
文本转换
LLM非常擅长将输入转换成不同的格式,典型应用包括多语种文本翻译、拼写及语法纠正、语气调整、格式转换等。
案例:语言识别
query="Якщо ви не їсте гарячий горщик, їжте жаровню."
prompt = f"告诉我以下文本是什么语种,直接输出语种,如法语,无需输出标点符号: ```{query}```"
lang = ask_llm(prompt)
print(f"原始消息 ({lang}): {query}\n")
原始消息 (乌克兰语): Якщо ви не їсте гарячий горщик, їжте жаровню.
案例:总结归纳(参数提取)
content="""
**Review of Panda Plush Toy**
**Introduction**
I bought this panda plush toy as a birthday gift for my daughter, who loves pandas as much as I do. This toy is very soft and adorable, and my daughter enjoys carrying it around with her everywhere. However, I also noticed some flaws in the toy’s design and size that made me question its value for money.
**Appearance and Quality**
The toy has a realistic black and white fur pattern and a cute expression on its face. It is made of high-quality material that feels smooth and gentle to the touch. One of the ears is slightly lower than the other, which may be a manufacturing defect or an intentional asymmetry to make it look more natural. The toy is also quite small, measuring about 12 inches in height. I expected it to be bigger for the price I paid, as I have seen other plush toys that are larger and cheaper.
**Delivery and Service**
The toy arrived a day earlier than the estimated delivery date, which was a pleasant surprise. It was well-packaged and in good condition when I received it. The seller also included a thank-you note and a coupon for my next purchase, which I appreciated.
**Conclusion**
Overall, this panda plush toy is a lovely and cuddly gift for any panda lover, especially children. It has a high-quality feel and a charming appearance, but it also has some minor flaws in its design and size that may affect its value. I would recommend this toy to anyone who is looking for a small and cute panda plush, but not to those who want a large and realistic one.
"""
prompt = f"""
针对以下三个反引号之间的英文评论文本,
首先进行拼写及语法纠错,
然后将其转化成中文,
再将其转化成优质淘宝评论的风格,从各种角度出发,分别说明产品的优点与缺点,并进行总结,回答内容不需要原文。
润色一下描述,使评论更具有吸引力。
输出结果格式为:
【优点】xxx
【缺点】xxx
【总结】xxx
注意,只需填写xxx部分,并分段输出。
将结果输出成Markdown格式。
```{content}```
"""
ask_llm(prompt)
**优点** 这款熊猫毛绒玩具外观可爱,质地柔软,适合孩子抱着玩耍。
**缺点** 毛绒玩具的设计有些瑕疵,尺寸较小,价钱与尺寸不太匹配。
**总结** 对于喜欢熊猫的孩子来说,这款熊猫毛绒玩具是个很不错的礼物,质地和外观都很迷人,但设计和尺寸方面有些小问题。适合想要小巧可爱的熊猫毛绒玩具的消费者,不适合追求更大更逼真的人群。
任务推断
推断任务可以看作是模型接收文本作为输入,并执行某种分析的过程。其中涉及提取标签、提取实体、理解文本情感等等。如果你想要从一段文本中提取正面或负面情感,在传统的机器学习工作流程中,需要收集标签数据集、训练模型、确定如何在云端部署模型并进行推断。这样做可能效果还不错,但是执行全流程需要很多工作。而且对于每个任务,如情感分析、提取实体等等,都需要训练和部署单独的模型。
LLM 的一个非常好的特点是,对于许多这样的任务,你只需要编写一个 Prompt 即可开始产出结果,而不需要进行大量的工作。这极大地加快了应用程序开发的速度。你还可以只使用一个模型和一个 API 来执行许多不同的任务,而不需要弄清楚如何训练和部署许多不同的模型。
prompt = f"""
请判断学生的解决方案是否正确,请通过如下步骤解决这个问题:
步骤:
首先,自己解决问题。
然后将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。
在自己完成问题之前,请勿决定学生的解决方案是否正确。
使用以下格式:
问题:问题文本
学生的解决方案:学生的解决方案文本
实际解决方案和步骤:实际解决方案和步骤文本
学生的解决方案和实际解决方案是否相同:是或否
学生的成绩:正确或不正确
问题:
我正在建造一个太阳能发电站,需要帮助计算财务。
- 土地费用为每平方英尺100美元
- 我可以以每平方英尺250美元的价格购买太阳能电池板
- 我已经谈判好了维护合同,每年需要支付固定的10万美元,并额外支付每平方英尺10美元
作为平方英尺数的函数,首年运营的总费用是多少。
学生的解决方案:
设x为发电站的大小,单位为平方英尺。
费用:
1. 土地费用:100x
2. 太阳能电池板费用:250x
3. 维护费用:100,000+100x
总费用:100x+250x+100,000+100x=450x+100,000
实际解决方案和步骤:
"""
ask_llm(prompt)
问题:计算太阳能发电站首年运营的总费用。
学生的解决方案:学生的解决方案正确,总费用为450x+100,000。
实际解决方案和步骤:实际解决方案也是将各项费用相加得到总费用,公式正确为总费用= 450x + 100,000。
学生的解决方案和实际解决方案是否相同:是
学生的成绩:正确
文本扩展
扩展是将短文本(例如一组说明或主题列表)输入到大型语言模型中,让模型生成更长的文本(例如基于某个主题的电子邮件或论文)。这种应用是一把双刃剑,好处例如将大型语言模型用作头脑风暴的伙伴;但也存在问题,例如某人可能会使用它来生成大量垃圾邮件。
review="这款AI数据库这个产品太棒了,性能上行业top,遥遥领先同行。特别的在生态建设上,大数据领域内自底向上的建设,并提供全链路加速,实时计算,大模型推理,与我司的业务场景深度融合,真正落地了AI赋能业务。"
sentiment="积极阳光,浮夸一点,高调一点"
prompt = f"""
你是一位客户服务的AI助手。
你的任务是给一位重要客户发送邮件回复。
根据客户通过“```”分隔的评价,生成回复以感谢客户的评价。提醒模型使用评价中的具体细节
用简明而专业的语气写信。
作为“AI客户代理”签署电子邮件。
客户评论:
```{review}```
评论情感:{sentiment}
"""
ask_llm(prompt)
尊敬的客户,
非常感谢您对我们AI数据库产品的积极评价!我们很高兴听到您认为我们的产品在性能和生态建设方面处于行业领先地位。特别是对于在大数据领域内提供全链路加速、实时计算和大模型推理等功能感到满意。我们一直致力于与客户的业务场景深度融合,真正实现AI技术赋能业务的目标。您的认可是我们不懈努力的最好回报,我们将继续努力提升产品质量,为您提供更优质的服务。
谢谢您对我们的支持!如果您有任何建议或需求,请随时与我们联系。
祝您一切顺利!
AI客户代理
